
The Bottom Line: Why the Difference Matters Today
You want to find information fast. Most people just head to Google. But did you know you might be missing out on 40% of the web by sticking to one algorithm? Traditional search engines like Google or Bing build their own indexes. They use ‘spiders’ to crawl the web and store that data on their own servers. It is a massive, expensive operation.

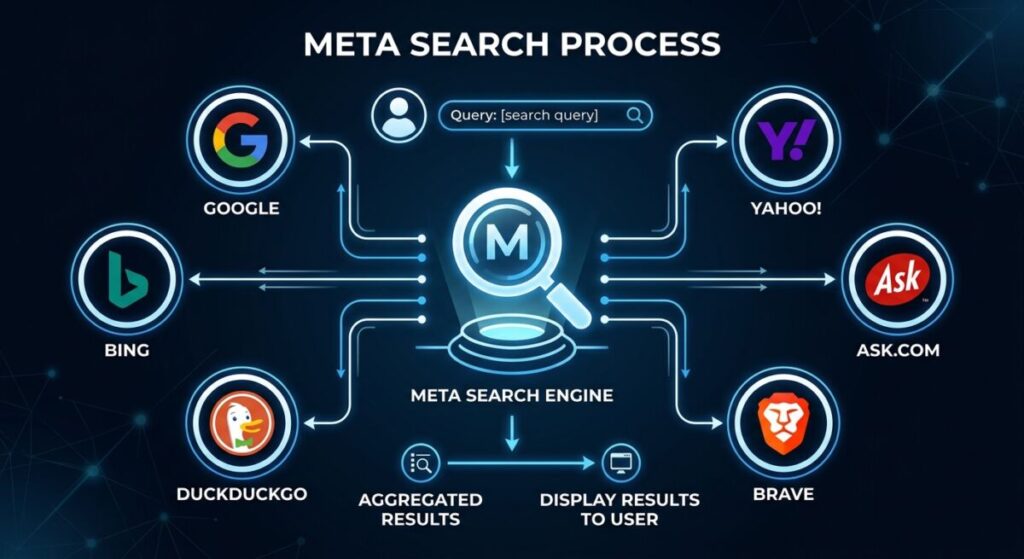
Meta search engines are different. They don’t crawl the web. Instead, they act as a middleman. When you type a query into a meta search engine, it sends that request to several traditional engines at once. It collects their results, cleans them up, and gives you a unified list. In our work at Infineural Technologies, we have found that meta search engines are often the best way to bypass the ‘filter bubbles’ created by big tech in 2026.
The Crawler vs. The Aggregator
Think of a traditional search engine as a chef who grows their own vegetables. They plant the seeds (crawling), harvest the crop (indexing), and cook the meal (ranking). They own the whole process. This gives them total control over the results. But it also means you only taste what that one chef thinks is good. If you are looking for more variety, check out our Top Search Engines List: 12 Best Platforms for Traffic (2026) to see the full variety available.
A meta search engine is more like a food delivery app. It doesn’t cook anything. It just looks at what five different restaurants are making and brings the best dishes to your door. It saves you time because you don’t have to visit five different sites. But it depends entirely on the quality of the ‘restaurants’ it pulls from. If Google and Bing are both having a bad day, the meta search engine will too.
Is one better than the other? Not necessarily. It depends on what you need. Traditional engines are great for deep, localized searches. Meta engines are better for broad overviews or when you want to see how different algorithms rank the same topic. Do you want to see the consensus or just one opinion?
How Traditional Search Engines Build an Index
Traditional engines spend billions of dollars on infrastructure. They need thousands of servers to store a copy of the internet. This process is called indexing. When you search on a traditional engine, you aren’t searching the ‘live’ web. You are searching their library of the web. This is why it takes time for new pages to show up. You have to wait for the spider to visit you. If you’re a site owner, you should submit your website to alternative search engines for free to speed this up.
In 2026, these spiders are smarter than ever. They don’t just look at keywords. They look at user intent, page speed, and even the ‘green’ credentials of your server. In fact, there are 7 surprising SEO benefits of hosting on a green server that many experts still ignore. These engines use complex math to decide who wins the top spot. It is a closed-door process that keeps SEO pros up at night.
As we navigate 2026, the definition of a ‘result’ has changed. We are no longer just looking for links; we are looking for synthesized answers. Traditional engines have integrated Large Language Models (LLMs) directly into their interfaces via Search Generative Experiences (SGE). However, this creates a new problem: AI bias. A meta search engine in 2026 doesn’t just aggregate links; it aggregates AI perspectives.
The Rise of the ‘Meta-AI’ Aggregator
Modern meta search platforms are now employing Multi-Model Rank Fusion. Instead of just pulling the top 10 links from Google and Bing, they pull the AI-generated summaries from multiple LLMs. They then use a secondary AI layer to compare these summaries, highlight consensus points, and flag contradictions. This provides a ‘meta-overview’ that is far more reliable than a single AI’s output. For professionals, checking the 9 top AI powered search engines for research shows how this technology is being used to verify facts in real-time.
Technical Challenges of Meta-Aggregation
The technical overhead for meta engines has increased. They must now handle API calls that include rich media, structured data, and generative text. This requires sophisticated deduplication logic. If three different engines provide the same AI-summarized fact, the meta engine must recognize the redundancy and present a single, verified insight. This process is similar to how developers use specialized search engines for code snippets to find the most efficient syntax across multiple repositories. By using a meta-approach, users gain the speed of AI with the verification of a multi-source index.
The Inner Workings of a Meta Search Engine
Meta search engines use something called ‘Rank Fusion.’ Since they get results from multiple sources, they have to decide which one to show first. If Google says a page is #1 but Bing says it is #10, where does the meta engine put it? They use algorithms like the Borda Count to find a mathematical average. This often results in a more ‘neutral’ list of results.
They also have to handle deduplication. You don’t want to see the same Wikipedia article five times just because five different engines found it. Meta engines strip out the repeats. This gives you a cleaner, more condensed view of the internet. Many researchers prefer this. If you are doing deep work, you might want to look at top search engines for academic research beyond Google Scholar to see how meta-analysis helps.
But there is a catch. Meta search engines often lack the advanced features of traditional ones. You might not get the ‘rich snippets’ or the interactive maps you see on Google. They are built for speed and breadth, not necessarily for ‘instant answers’ like the modern AI-driven traditional engines we see in March 2026.
In 2026, data sovereignty has become the primary driver for search engine migration. Traditional engines like Google or Bing rely on massive user profiles to serve personalized results. While this ‘personalization’ is convenient, it creates a digital footprint that many users now find intrusive. This is where meta search engines offer a distinct architectural advantage: Proxy Searching.
Anonymity through Aggregation
When you use a privacy-focused meta search engine, your query is scrubbed of identifying metadata—such as your IP address, browser fingerprint, and tracking cookies—before being passed to the traditional engines. The meta engine acts as a ‘buffer,’ making the request on your behalf. To the traditional engine, the request appears to come from the meta engine’s server, not your device. This makes it significantly harder for big tech to build a profile on your searching habits.
For those prioritizing absolute data security, comparing DuckDuckGo vs Startpage for privacy-conscious users is essential to understand how different meta-architectures handle your data. Some meta engines even use encrypted tunnels to ensure that even your ISP cannot see the specific terms of your search. In an era of hyper-targeted advertising, this layer of separation is the best way to maintain a ‘clean’ search experience without the influence of past behavior.
Bypassing the Filter Bubble
Traditional engines use your past history to predict what you want to see. This leads to the ‘Filter Bubble,’ where you are only shown information that confirms your existing biases. Meta search engines break this cycle by pulling from diverse indexes simultaneously. By aggregating results from multiple sources, they provide a cross-section of the internet that is closer to the objective truth. If you are looking for an unbiased overview of a topic, using one of the best private search engines that don’t track data is a strategic necessity for researchers and marketers alike.
Privacy: The Hidden Driver of Meta Search in 2026
Why are people flocking to meta search engines lately? One word: Privacy. Traditional engines make money by tracking you. They build a profile of your interests and sell it to advertisers. Meta engines like Startpage or DuckDuckGo (in its meta capacity) act as a shield. They send your query to the big engines anonymously. The big engines see the query, but they don’t see *you*.
This is a big deal in 2026. Data privacy is no longer a niche concern. It is a mainstream demand. If you’re wondering which one to use, we did a deep dive on DuckDuckGo vs Startpage for privacy-conscious users. Using a meta engine is often the easiest way to get ‘Google-quality’ results without the ‘Google-quality’ tracking. It’s a win-win for most users.
But keep in mind, ‘free’ meta engines still need to pay the bills. They usually do this through contextual ads. These ads are based on what you searched for *right now*, not what you searched for three weeks ago. It is a much more ethical way to monetize. And honestly? The ads are usually less annoying.
Speed and Efficiency: A Real-World Comparison
Is a meta search engine slower? Technically, yes. It has to wait for multiple other engines to respond before it can show you the results. In 2026, we’re talking about milliseconds, but it’s there. Traditional engines are faster because they are pulling from their own local database. They don’t have to wait for anyone else.
However, the ‘efficiency’ of a meta search engine is higher. If you have to search three different sites to find a rare piece of information, that takes minutes. A meta engine does it in seconds. We see this often when clients are looking for rare data. If you’re searching for something specific, like best video search engines for finding rare content, a meta approach is almost always better.
Don’t let the millisecond delay fool you. The time you save by not hopping between tabs is much more valuable. For power users, meta search is the ultimate productivity hack. It simplifies the discovery process and cuts through the noise of biased algorithms.
The Role of AI in 2026 Search
By March 2026, AI has changed everything. Traditional engines are now ‘answer engines.’ They don’t just give you links; they give you paragraphs of text. This is great for simple questions, but it can be dangerous for complex ones. AI can hallucinate. It can be biased. It can present one perspective as the absolute truth.
Meta search engines provide a necessary check. By showing you results from multiple AI models and traditional indexes, they allow you to spot discrepancies. If three different engines give three different answers, you know you need to dig deeper. This ‘triangulation’ is the only way to stay informed in an AI-heavy world. We always tell our clients at Infineural Technologies: never trust a single source of truth online.
And let’s talk about SEO. If you want to rank in 2026, you can’t just optimize for one engine. You need to look at the broader picture. Meta engines show you the ‘consensus’ of the web. If you’re appearing in meta results, it means multiple algorithms have vetted your content. That is a very strong signal of authority. Want to know more? Check out these 11 hidden ranking factors for niche websites.
Which One Should You Choose?
So, which should you use? It’s not an either-or choice. Most savvy users in 2026 use both. Use traditional engines for local searches, shopping, and quick facts. Their integration with your local environment is hard to beat. If you need a plumber in your zip code, Google is your best bet.

Use meta search engines for research, privacy-sensitive topics, and when you feel like you’re stuck in an algorithmic bubble. If you feel like you’re seeing the same five websites over and over, switch to a meta engine. It will break the cycle. It will show you the parts of the web that the big algorithms might be hiding.
The web is too big for one engine to map perfectly. Even in 2026, with all our advanced AI, we still need variety. Diversity in search is just as important as diversity in news. Don’t let a single algorithm decide what you know. Experiment. Try new tools. You might be surprised at what you find.
Take Control of Your Search Strategy
Understanding the difference between these tools is just the first step. In the fast-moving world of 2026, you need a search strategy that is as dynamic as the web itself. Whether you are looking to increase your site’s visibility or just find better information, diversification is key. At Infineural Technologies, we help brands navigate this complex world. We don’t just follow the trends; we anticipate them. Ready to see how your brand stacks up across the entire search ecosystem? Let’s build something better together. Reach out to us today to start your journey toward search mastery.

Deciding between a meta engine and a traditional engine depends entirely on your ‘Search Intent.’ At Infineural, we categorize search tasks into three distinct buckets to help our clients optimize their discovery strategies.
- Deep Vertical Search: If you are looking for a specific local business in Nashik or a very recent news update, traditional engines are superior. Their ‘spiders’ crawl high-frequency sites more often, providing better real-time data. For example, when looking for the best SEO company in Nashik, a traditional engine’s local map pack is unbeatable.
- Broad Academic or Technical Research: When you need to see the ‘totality’ of a topic, meta search engines are the gold standard. They allow you to see how different algorithms value the same content. This is particularly useful when exploring academic research and scholarly articles, where missing a single database could mean missing a breakthrough.
- Privacy-Sensitive Queries: If you are researching a medical condition, legal advice, or competitive business intelligence, a meta engine is mandatory. Traditional engines will tag your profile with these interests, leading to months of targeted ads. Meta engines keep your research private.
Ultimately, the best search strategy in 2026 is a hybrid one. We recommend using a traditional engine for your daily navigation and a meta engine for your deep-dive research. To see the full scope of what is available, browse our comprehensive list of 50 search engines to diversify your traffic.
Frequently Asked Questions
What is the main difference between a meta search engine and a traditional one?
Traditional engines crawl and index the web themselves, while meta engines aggregate results from multiple traditional engines.
Are meta search engines safer for privacy?
Yes, most meta engines act as a proxy, hiding your IP address and personal data from the major engines they query.
Does a meta search engine have its own database?
No, meta search engines do not store their own index of web pages; they rely on the indexes of other providers.
Why are traditional search engines faster?
They pull data from their own local servers rather than waiting for third-party APIs to respond with results.
Can I use meta search engines for SEO research?
Absolutely, they are excellent for seeing how different algorithms rank your site compared to your competitors.
Is Dogpile still a meta search engine in 2026?
Yes, Dogpile remains one of the oldest and most well-known meta search engines, still aggregating from Google and Yahoo.
Do meta search engines show different results than Google?
Yes, because they blend Google’s results with those from Bing, Yandex, and others, the final ranking order is unique.
Are meta search engines free to use?
Almost all meta search engines are free, supported by contextual advertising rather than invasive data tracking.
Is Google a meta search engine?
No, Google is a traditional search engine. It uses its own proprietary crawlers (Googlebot) to index the web and stores that data on its own servers. A meta search engine, by contrast, does not have its own index and instead pulls results from Google and other engines simultaneously.
What are the main advantages of meta search engines?
The primary advantages are increased privacy, broader coverage, and the elimination of ‘filter bubbles.’ By aggregating results from multiple sources, they provide a more neutral view of the web and prevent a single algorithm from controlling what information you see.
Are meta search engines better for privacy than Google?
Yes, most meta search engines like Startpage or Dogpile act as a proxy. They strip your IP address and tracking data before sending your query to traditional engines, ensuring that your search history isn’t linked to your personal identity.
Why do some results look different on meta search engines?
Meta engines use ‘Rank Fusion’ algorithms to decide the order of results. Because they are averaging the rankings from multiple sources like Bing, Google, and Yahoo, the final list often looks different—and often more diverse—than any single engine’s results.


